Reference Sample Product¶
$SetSchemaPath phz/euc-test-phz-ReferenceSample.xsd
Data Product Name¶
$PrintDataProductName
Data Product Custodian¶
$PrintDataProductCustodian
Name of the Schema File¶
$PrintSchemaFilename
Data Product Elements¶
$PrintDataProductElements
Schema documentation tag¶
Documentation for data product element dpdReferenceSample:
Represents the reference sample used by NNPZ algorithm. This is produced outside the pipeline and follows an internal binary format.
Documentation for data product element Header:
The generic header of the product.
Detailed Description of the Data Product¶
Reference sample used by NNPZ algorithm.
Processing Element(s) creating/using the data product¶
This data product is produced outside the Euclid pipeline using the Phosphoros tool
and is manually ingested in the EAS. * It is used as input of the NNPZ component of the PHZ PF.
Processing function using the data product¶
This product is produced by the PHZ Calibration Pipeline and used in the PHZ Production Pipeline.
This product contains four types of files representing the NNPZ reference sample:
Index¶
The index file contains information to easily retrieve the SED template and PDZ data. The information of each reference sample object is stored sequentially in the following way:

The first 8 bytes contain the object identifier as a long signed integer
The next 2 bytes contain the file index in which the SED is located, as a sort unsigned integer
The next 8 bytes contain the position of the SED of the object in the SED data file, as a long signed integer
The next 2 bytes contain the file index in which the PDZ is located, as a sort unsigned integer
The last 8 bytes contain the position of the PDZ of the object in the PDZ data file, as a long signed integer
SED template data files¶
Because of the high volume of the SED template data, there are multiple of such files, to limit the size of each file to around 1GB. The files are named sed_data_XX.bin, where the XX is the number of the file. The data of each template are stored sequentially in the following way:

The first 8 bytes of the template is its identifier (a long signed integer)
The next 4 bytes contain the number of points (n) the template consists of (as an unsigned integer)
The length is followed by the template data, organized in pairs of single precision decimal values (4 bytes), representing the wavelength and the flux density of the template.
Note that the SED templates can have different number of points from each other.
PDZ data files¶
The PDZ data files store the Redshift Probability Density Function produced using higher quality photometry. The files are named pdz_data_XX.bin and the splitting of the files follows the same rules like the SED template files. The file is organized the following way:
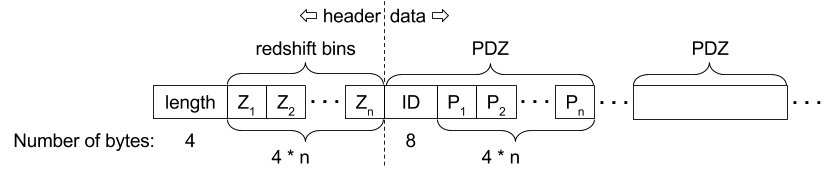
The first 4 bytes contain the number of points (n) that each PDZ consists of (as an unsigned integer)
The length is followed by n single precision decimal values (4 bytes each) representing the redshift bin values
This concludes the header part of the file, which contains information common to all PDZs. Note that this information is duplicated to all of the PDZ data files.
After the header, the PDZ data are stored sequentially
The first 8 bytes of the PDZ is the SED identifier (a long signed integer)
The ID is followed by n single precision decimal values (4 bytes each), representing the PDZ value for each redshift bin.
Photometry¶
A FITS file containing the photometry values of the sample for a set of reference filters, and the filter transmissions.
The first HDU has the extension name (EXTNAME header keyword), which is always set to the string NNPZ_PHOTOMETRY. This name is used by NNPZ to detect photometry files, so it should never be changed.
The header also contains the keyword PHOTYPE which indicates the type of the photometry values stored in the file. The different photometry types are the following:
Photons: The photometry values are photon count rates, expressed in counts/s/cm2
F_nu: The photometry values are energy flux densities expressed in erg/s/cm^2/Hz
F_nu_uJy: The photometry values are energy flux densities expressed in {\mu}Jy
F_lambda: The photometry values are energy fluxes densities expressed in erg/s/cm^2/\AA
MAG_AB: The photometry values are AB magnitudes
The first column of the table is always named ID and contains 64 bit signed integers, which match the identifiers of the reference sample objects. The rest of the columns contain 32 bit floating point numbers and represent the photometry values. The names of the bands are extracted from the column names. The bands can optionally have an error associated with them, in which case there must be a column with the same name and the postfix _ERR. For example, if the table contain a column named g, the error column must be named g_ERR.
The rest of the HDUs in the fits file contain the filter transmissions of the bands. They are binary tables with two columns, the first of which contains the wavelength values (expressed in \AA) and the second the filter transmission (a number in the range [0,1]). Both columns contain 32 bit floating point numbers. The extension names (EXTNAME header keyword) is the same with the band name and it is used for identifying the filter transmissions (the order does not matter).